How Large Language Models Are Reshaping the Way Search Engines Rank Content in 2026?
Something fundamental shifted in how search engines work between 2022 and 2025 — and most content strategies haven’t caught up with it yet. The shift isn’t cosmetic. It’s structural. The underlying mechanism by which Google decides what to surface, what to cite, and what to answer directly has changed from a keyword-matching system to a semantic understanding system — and large language models are at the centre of that change.
This post explains what that actually means in technical terms, how Google’s AI Overviews (formerly SGE) alter the competitive landscape, what entity salience is and why it matters more than keyword density, and what content strategy looks like when you’re optimising for a model’s understanding rather than a crawler’s index.
This is not a post about ChatGPT as a competitor to Google. It is about how LLMs have been integrated into Google’s own ranking and retrieval infrastructure — and what that means for content that wants to be found.
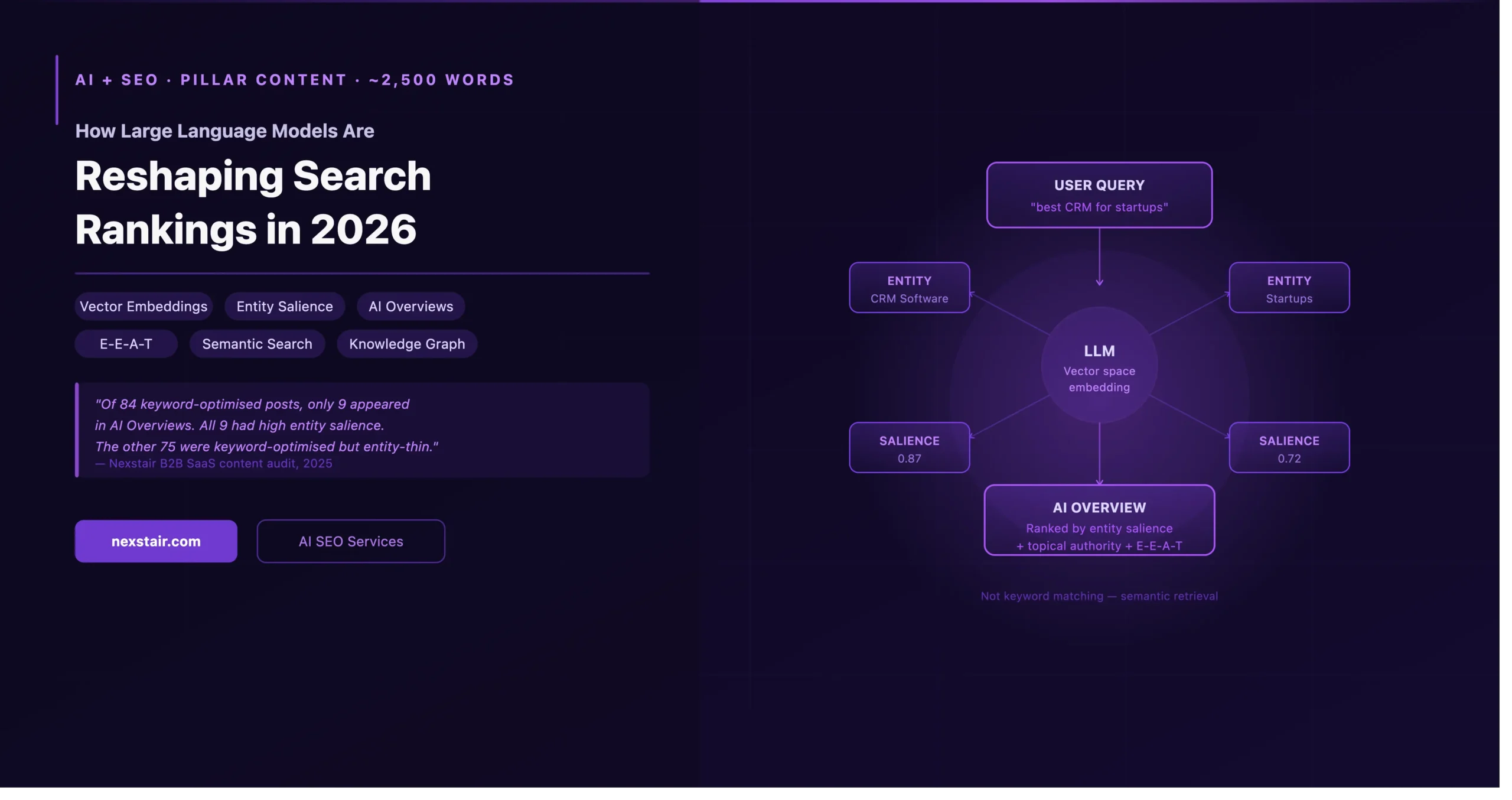
In early 2025, Nexstair audited the content performance of a B2B SaaS client whose blog had been publishing keyword-targeted articles for two years. Of 84 published posts, 61 had measurable keyword rankings but only 9 appeared in AI Overviews for the same queries. The 9 that appeared shared three characteristics: they defined entities clearly in the opening section, they covered related concepts in the same article (topical depth), and they were cited by at least two other authoritative domains covering the same topic. The other 75 were keyword-optimised but entity-thin — and the AI Overview layer was passing them over entirely.
What LLMs Are (and Aren’t)
A large language model is a neural network trained on a massive corpus of text to predict the most statistically likely next token — word fragment — given everything that precedes it. That’s the mechanical description. What emerges from that process, at sufficient scale, is something more interesting: a model that has internalised an implicit map of how concepts, entities, and ideas relate to each other across the entire training corpus.
This is fundamentally different from how a traditional search index works. A keyword-based index maps strings to documents. A vector-based retrieval system — which is what LLM-integrated search uses — maps meaning to documents. The query “how do I reduce my site’s loading time” and the query “page speed optimisation techniques” are processed as similar, because they occupy similar positions in the model’s semantic space. Neither requires the exact string “page speed” to appear in the document for it to be retrieved.
What LLMs are not
LLMs are not search engines. They are not databases. They do not look things up — they generate responses based on patterns learned during training, which is why they hallucinate: they are optimised to produce plausible text, not accurate text. The distinction matters because Google does not use a raw LLM as its search engine. It uses LLM-derived representations — specifically, vector embeddings — as part of a broader retrieval and ranking pipeline that also includes its traditional index, PageRank derivatives, and human quality rater feedback.
Understanding this distinction prevents two common misconceptions: that traditional SEO is dead (it isn’t — links, technical quality, and crawlability still matter), and that you can optimise for LLMs the same way you optimise for GPT-4 (you can’t — Google’s implementation is proprietary and continuously updated).
Vector embeddings and why they matter for content
When Google processes a piece of content, it converts it into a high-dimensional vector — a list of numbers that represents the semantic position of that content in conceptual space. Documents that discuss similar topics, reference similar entities, and use similar conceptual vocabulary end up near each other in this space, regardless of whether they share exact keywords.
This is why two pages can rank for the same query without using the same words. It’s also why a page that covers a topic superficially — hitting the primary keyword but not the surrounding concepts — performs worse in LLM-influenced rankings than a page that covers the topic with genuine depth, even if the shallow page has more backlinks.
How SGE Changes Rankings
Google’s AI Overviews — launched as Search Generative Experience in 2023 and rolled out broadly in 2024 — place a synthesised, cited answer at the top of search results for a large and growing proportion of queries. By mid-2025, AI Overviews were appearing for an estimated 40–50% of informational and navigational queries in English-language results.
The zero-click problem and the citation opportunity
The immediate concern from an SEO perspective is zero-click results: if the AI Overview answers the question completely, users have no reason to click through to any source. Early data on AI Overview CTR impact has been mixed — some analyses show 15–25% reductions in clicks for queries where overviews appear, while others show that cited sources receive increased visibility because they appear above the traditional organic results, not below them.
The more useful frame is not “will AI Overviews reduce my traffic” but “will my content be cited in AI Overviews, or bypassed by them.” Being cited in an overview for a competitive query is equivalent to a featured snippet in 2018 — it signals authority and captures attention even if it doesn’t always capture the click. Being bypassed means your content isn’t being recognised as authoritative on the topic, regardless of its keyword ranking.
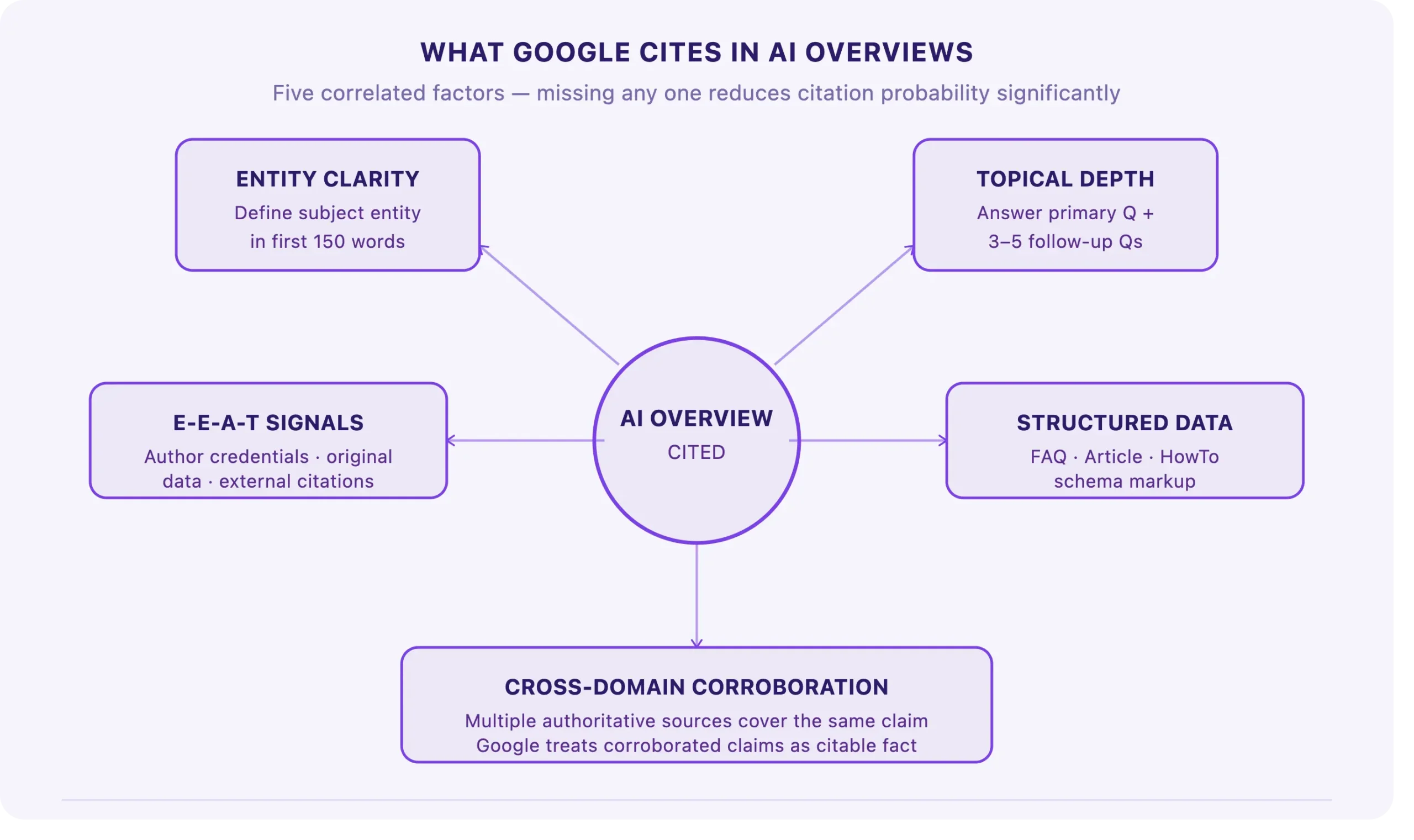
What Google cites in AI Overviews
Based on patterns observed across Nexstair client accounts and industry research through early 2026, AI Overview citations correlate strongly with:
- Entity clarity: content that defines its subject entity explicitly in the first 150 words, with clear relationships to adjacent entities
- Topical completeness: content that answers the primary question and the three to five most common follow-up questions within the same page
- E-E-A-T signals: author credentials, original data or case studies, external citations, and organisational about pages that establish expertise
- Structured data: FAQ schema, Article schema, and HowTo schema help Google’s pipeline parse and attribute content accurately
- Cross-domain corroboration: when multiple authoritative sources cover the same claim, Google’s system is more likely to treat it as citable fact rather than an individual opinion
A practical implication: the content most likely to be cited in AI Overviews is not the content optimised for a single target keyword. It is the content that functions as a mini reference document on a specific topic — clear, complete, structured, and corroborated. This is a fundamentally different brief than “write a 1,500-word article targeting [keyword].”
Entity Salience Explained
Entity salience is one of the least-discussed but most consequential concepts in modern SEO. It refers to the degree to which a given entity — a person, place, organisation, concept, or thing — is a central, definitional subject of a piece of content, as opposed to merely mentioned in passing.
Google’s Natural Language API assigns salience scores to entities detected in content. A score close to 1.0 means the entity is central to the document. A score close to 0.0 means it’s peripheral. The salience score is determined not just by how many times the entity appears, but by how structurally central it is — whether it appears in the title, early in the body, in headings, and in contexts that establish its attributes and relationships rather than just referencing it.
Why salience beats keyword density
Keyword density optimisation — repeating a target phrase a certain number of times per 1,000 words — was a meaningful signal in the pre-LLM era because crawlers relied heavily on string matching. Entity salience operates differently: Google’s systems evaluate whether your content understands the subject, not just whether it mentions it. A page that mentions “content marketing” fourteen times but never discusses its relationship to brand authority, conversion funnels, or audience segmentation has low entity salience for content marketing. A page that discusses content marketing in relation to those concepts — even without the phrase appearing frequently — has high salience.

Practical entity optimisation
- Define the primary entity in the first paragraph. State clearly what it is, what category it belongs to, and what it does or means.
- Cover the entity’s key attributes and relationships. For a product: features, use cases, comparisons, limitations. For a concept: definition, history, applications, common misconceptions.
- Use the entity’s associated vocabulary naturally. Google’s Knowledge Graph maps entities to co-occurring terms. Content that uses those terms signals genuine topical authority.
- Link to and from authoritative entity pages. Internal links that connect related entity pages strengthen the topical cluster signal. External links to authoritative sources corroborate your coverage.
- Implement relevant schema. Schema markup makes entity relationships machine-readable, reducing the inference work Google has to do and increasing the likelihood of accurate attribution.
The practical difference between keyword-based and entity-based optimisation is significant enough to warrant a structural shift in how content briefs are written. The table below maps the key dimensions side by side.
| Dimension | Keyword-based SEO | Entity-based SEO |
| Core unit | Keyword string | Entity and concept |
| Ranking signal | Keyword frequency, backlinks, anchor text | Topical authority, entity salience, co-occurrence |
| Content model | Optimise for a target query | Build a topic cluster around an entity |
| Search intent | Inferred from keyword | Modelled from user context and behaviour |
| Duplicate risk | Keyword stuffing, thin content | Thin entity coverage, missing relationships |
| Measurement | Keyword position tracking | Visibility across entity-related queries |
| LLM relevance | Partially understood by models | Native to how LLMs process and retrieve knowledge |
What This Means for Your Strategy
The transition from keyword-based to LLM-influenced ranking doesn’t invalidate existing SEO investment — it recontextualises it. Technical SEO, crawlability, page speed, and backlinks remain important. What changes is the content layer: what you write, how you structure it, and how you measure whether it’s working.
Audit for entity coverage, not just keyword rankings
Run your existing content through Google’s Natural Language API (it’s free for small volumes). Check the salience scores for your primary target entities. Content with salience below 0.4 for its primary subject is likely underperforming in LLM-influenced results regardless of its keyword ranking. Salience below 0.2 suggests the content is covering the entity incidentally — it’s not a reference document on the topic and Google won’t treat it as one.
Build topic clusters around entities, not keyword families
A keyword family for “SEO services” might include: “SEO services for small business,” “affordable SEO services,” “best SEO agency.” An entity cluster for the same concept includes the pillar page on SEO services, supporting pages on technical SEO, local SEO, on-page optimisation, and content strategy — each covering a distinct aspect of the parent entity with its own salience, and all internally linked.
The cluster approach builds topical authority — Google’s assessment of how comprehensively your site covers a subject area. High topical authority for a given entity is a stronger signal than high keyword rankings for individual terms, because it reflects genuine depth rather than page-level optimisation.
Optimise for citation, not just ranking
For informational content in 2026, the success metric is no longer position 1 for the target keyword. It is: does this content appear in AI Overviews for the queries it targets? Is it being cited as a source? Is it appearing in zero-click formats that build brand visibility even without click-through?
These require different inputs: structured data, explicit entity definitions, original data points, and clear author attribution. None of these are traditional ranking factors — they are citation factors, and they are increasingly what determines whether a piece of content contributes to organic visibility in 2026.
If your current content strategy was built around keyword research and position tracking and hasn’t been updated in the past 18 months, it’s likely operating on assumptions that no longer fully reflect how ranking works. Working with an ai seo agency that understands both the LLM layer and the traditional technical foundation is the fastest way to identify where the gaps are and close them.
Frequently Asked Questions
| What is the difference between keyword-based SEO and entity-based SEO? |
| Keyword-based SEO optimises content to match specific search strings — placing target phrases in titles, headings, and body text at calculated frequencies. Entity-based SEO optimises for semantic understanding — ensuring that Google’s systems recognise your content as a comprehensive, authoritative reference on a specific entity (a concept, person, product, or place) and its related attributes. The practical difference is that entity-based content ranks for a cluster of semantically related queries, not just the target keyword, and is more likely to be cited in AI Overviews. |
| How does Google’s Search Generative Experience affect organic click-through rates? |
| The impact varies by query type. For purely informational queries — definitions, how-to questions, factual lookups — AI Overviews can reduce click-through rates by 15–25% by answering the question directly. For commercial, navigational, and complex research queries, the effect is more mixed: cited sources often see increased visibility because they appear above traditional organic results. The strategic response is not to avoid informational content but to ensure your content is cited in overviews rather than bypassed by them — which requires entity clarity, topical completeness, and structured data. |
| What is entity salience and how does it influence search rankings? |
| Entity salience is a score (0 to 1) assigned by Google’s Natural Language Processing systems to each entity detected in a piece of content, indicating how central that entity is to the document. A salience score near 1.0 means the entity is the primary subject. A score near 0.0 means it’s mentioned in passing. High salience for a target entity correlates with stronger ranking across the full cluster of related queries, not just the primary keyword, because Google’s systems interpret high-salience content as a reference document on the topic rather than a page that happens to mention it. |
| Do LLMs replace traditional keyword research entirely? |
| No. Keyword research remains valuable for understanding search demand, identifying query patterns, and measuring visibility — but it no longer drives content structure the way it once did. The shift is from using keywords as the primary brief (“write content targeting X keyword”) to using entities as the primary brief (“build a comprehensive reference on X entity that covers these attributes and relationships”). Keyword data informs which entities have search demand; entity analysis determines how to cover them. Both inputs are needed — neither alone is sufficient in 2026. |
The Shift Is Already Priced In
The businesses whose content is performing in 2026 are not the ones that reacted to AI Overviews by writing more content, faster. They are the ones that stepped back, audited what Google’s systems actually understood about their topics, and rebuilt their content architecture around entities, topical authority, and citation-worthiness rather than keyword density and volume.
This is a harder brief. It requires genuine expertise, original perspectives, and structural discipline. It cannot be outsourced to a content mill or automated with a basic AI writing tool. But it produces a fundamentally more durable competitive position — because content that Google’s systems recognise as genuinely authoritative on a topic compounds in value over time, while content optimised for last year’s ranking model continues to erode.
If you want to understand where your current content sits on this spectrum — which pieces have strong entity salience, which are being cited, and which are quietly losing ground — the right starting point is an audit. A proper one, not a keyword position report. We work as an ai digital marketing agency that approaches content through both the LLM lens and the technical SEO foundation — because neither alone tells the full story.
Contact Info
Recent Posts
Related Posts
How Large Language Models Are Reshaping the Way Search Engines Rank Content in 2026?
Something fundamental shifted in how search engines work between 2022 and 2025 — and most content strategies haven't caught up...
What a Technical SEO Audit Actually Examines and Why Most Agencies Miss Half of It?
A technical SEO audit is one of the first things any reputable agency should offer — and one of the...
Google Business Profile Optimisation: The Signals That Determine Who Wins the Local Pack
Search "plumber near me" or "best coffee shop in [city]" and the first thing you see isn't a list of...
AI Agents vs Workflow Automation: Understanding the Difference and When to Use Each
The term "automation" is doing a lot of heavy lifting in marketing conversations right now. It covers everything from a...
E-commerce SEO Architecture: How Product Pages, Category Pages, and Internal Links Work Together to Drive Revenue
Most e-commerce store owners treat SEO as a checklist: write a title tag, add a meta description, drop in a...